
What is semantic segmentation?
Semantic segmentation is a pixel-wise classification problem statement. If until now you have classified a set of pixels in an image to be a Cat, Dog, Zebra, Humans, etc then now is the time to learn how you assign classes to every single pixel in an image. And this is made possible through many algorithms like semantic segmentation, Mask-R-CNN.
In this article, we will learn about the implementation of semantic segmentation using a deep learning model which has performed exceedingly well in the field of biomedical image segmentation called U-Net.
The network can be trained end-to-end with very few images and outperforms the prior best methods of segmentation.
A few years back I build an application using GrabCut by OpenCV to performed semi-automatic segmentation (Human in a loop) on images where my objective was to segment the foreground and background in an image, it was workable then but not a scalable solution.
Then my problem statement changed to segment image in such a way that I was required to segment multiple objects present in the image and the one those are segmented we give same labels if they belong to the same class.
Solving the above problem statement was not feasible using GrabCut.
In this article, we are going to train the U-Net model to build an application which can automatically annotate buildings on the 2D satellite images. I am going to train it for two classes only. One building and another background.
You can train it for multiple classes. You can train the model on your dataset. You just need to follow similar steps as I am going to train on my dataset which contains 2D satellite images.
Project structure
|------U-Net
| |------data
| | |------train
| | | |-----|Folder_1
| | | | |------|images
| | | | |------|------|Folder_1.png
| | | | |------|masks
| | | | |------|------|Folder_1_mask_1.png
| | | | |------|------|Folder_1_mask_2.png
| | | | |------|------|Folder_1_mask_3.png
| | | | |------|------|Folder_1_mask_4.png
| | | | |------|------|Folder_1_mask_......png
| | | | |------|------|Folder_1_mask_n.png
| | | |-----|Folder_n
| | | | |------|images
| | | | |------|------|Folder_npng
| | | | |------|masks
| | | | |------|------|Folder_n_mask_1.png
| | | | |------|------|Folder_n_mask_2.png
| | | | |------|------|Folder_n_mask_3.png
| | | | |------|------|Folder_n_mask_4.png
| | | | |------|------|Folder_n_mask_......png
| | | | |------|------|Folder_n_mask_n.png| | |------test
| | | |-----|Folder_2
| | | | |------|images
| | | | |------|------|Folder_2.png
| |------code
| | |------train
| | | |------|train_unet.py
| | | |------|train.ipynb
| | |------test
| | | |------|test.py
| | |------util
| | | |------|resize.pyYou can download the whole project by clicking on this text.
Always remember to follow Keras 7 steps to build a Deep learning model.
1. Analyze the dataset
2. Prepare the dataset
3. Create the model
4. Compile the model
5. Fit the model
6. Evaluate the model
7. SummaryCreate your dataset
Analyze and prepare the dataset
This is the most important step I would say while you are trying to train any deep learning model. Good analysis and understanding of the data that you would be using to train you deep learning model will help you to choose your hyperparameter, matrices, loss functions, optimizers in a mindful way. It will save you from overfitting, underfitting, save your time and resources.
I would recommend data augmentation only when you are ready to dedicate a good amount of time carefully cross-checking the quality of the augmented data. But if you can not afford the time and still want to use the augmented data something which I least recommend would be outsourcing the image pre-processing step. To be very true I do not trust the outsourcing process. It incurs a huge amount of time and when you do not see the expected results you panic and it becomes more of rework.
I annotate all my training images, build my models, train and test them.
Recently, A deep learning enthusiast (Leader) asked me a few things I wish to do. One of my answers was “ Wish to work with the support of labeling team”. Hearing this he gave me some time to modify my statement if I wished. After giving a thought I replied, “ Wish to work with and within of labeling team, sitting among them”. He was happy with my “Deep thoughts”. Yes, my dear friends when you have to label/annotate a huge number of data, you will need a team to help you do that. Then I can recommend you to sit with the labeling team and take good care that your data is getting correctly annotated. Do not allow people to talk, sleep, eat, look into their cell phones, daydream and annotate your data. No no no that is not allowed. Data is data.
Few major steps before creating your dataset should be understanding the
Data requirements
The number of classes, quality, and quantity of available data versus the required data.
Data collection
Data are collected from a variety of sources. The data may also be collected from sensors in the environment, such as traffic cameras, satellites, recording devices, etc. It may also be obtained through interviews, downloads from online sources, or reading documentation.
Data processing
Data initially obtained must be processed or organized for analysis. For instance, these may involve placing data into rows and columns in a table format for further analysis, such as within a spreadsheet or statistical software or placing the images and its annotation in a text, JSON file.
Data cleaning or post-processing
Once the data is processed and organized, the data may be incomplete, contains noise, contain duplicates, broken or may be corrupted. Particularly with respect to image processing data cleaning involves find extremum, image normalization, denoising, skew correction, resize the image, boost or smoothen the edges, illumination correction, color space conversion, region processing, thresholding, build clusters, find the correlation. Verifying the annotations and labels.
I am training on 2D satellite images, my image requirement was to build a dataset of 2D satellite image which has buildings in it as I am trying to classify the buildings from the background. The dataset should be unbiased, should have a good pixel density, high definition images, a large amount of data, masks corresponding to each image where the buildings are accurately annotated. The data processing and organizing required here was generating mask images as I received a text file where the annotation information which is the x and y coordinate points was mentioned. To give you an example my annotations in a text file looked like this:
[[441, 562], [441, 529], [458, 529], [458, 520], [472, 520], [472, 528], [475, 528], [475, 561], [441, 562], [545, 541], [545, 520], [573, 520], [573, 541], [545, 541], [545, 541]]
When you are creating your dataset you might find the annotations in a text, JSON, spreadsheet and if you are lucky you might receive the complete mask.
After you have the masks you need to place the images and the masks in the structure shown above. I used OpenCV to create masks. You can find the code for this in the util folder. You might want to refer my code. Now divide the available data into two sections train and test. Keep 70 percent of images for training and 30 percent of image for testing. Never use your training images for testing.
Create the U-Net model
Import dependencies
I have shared a dependencies requirement file with the project.You can find the requirement file in the code folder. You can install all the libraries by creating a new virtual environment using the below commands. The libraries are numpy, pandas, matplotlib, tqdm, sci-kit image learn, Keras, tensorflow, OpenCV.
sudo apt update
sudo apt install python3-pip
pip3 --version
pip3 install virtualenv
virtualenv venv
source venv/bin/activate
pip3 install -r requirement.txtLine 1 to 7- I have defined the input image dimensions. It is 128x128x3 and the mask is 128x128. The path of the train and testing folders are defined here on line 6 and 7.
Line 9 to 18- It is used to cancel all the randomness from python and random libraries. Line 17 and 18, It makes a list of all the image folders used in the training and testing folders.
Line 21,22- We create tensors to load the input image and its mask. In line 24 and 25 you can see the shape of your dataset. You can manually cross-check the number with the number of training samples you have.
Line 28 to 38- This is the block of code where the image and mask files are read from folders, resized and loaded in the tensors X_train and Y_train respectively. If the size of your image is large, then loading the data will incur a good time. Loading 720 images once took me 2 hours on 8 core CPU.
Line 40 to 49- As I have loaded the input image and its masks. Now is the time to load the test images. The test images are loaded in the tensor, X_test. In this block of code, the test images are read, resized, loaded.
Train U-Net model
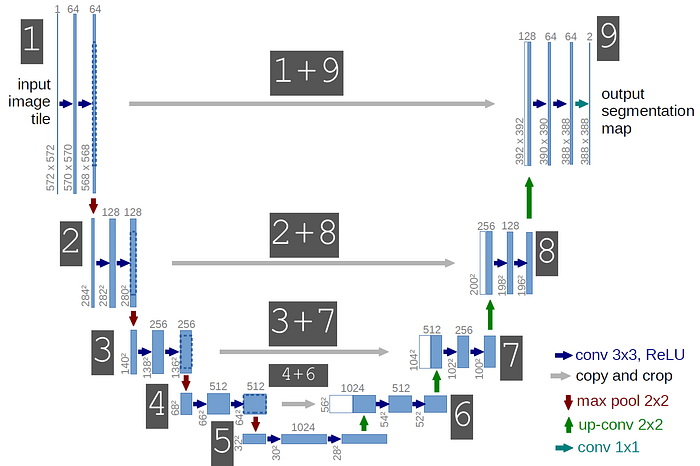
The model contains 23 convolutional layers. The number of convolutional layers are 19 and transposed convolution layers are 4.
Line 2 to 3- The size of the input image is 128X128X3 and its mask is of the size 128X128. Followed by two consecutive convolution layers. Each layer uses 64 filters of size 3X3. I have normalized the image pixels between 0 and 1 by dividing all the pixels in the image by 255, as I am using an 8-bit image.
Line 5 to 8- On line 5 the layer c1 is the first convolution layer, in this convolution layer I have used 16 filters each of size 3x3. The activation function used is the Exponential linear unit(ELU) and “he_normal” is the weight initialization method. To read more about the reason behind using ELU and “he_normal”, please refer to part-1 of this series.
Line 6 The output of the layer c1 goes to a dropout layer where 0.1 nodes are dropped out during both forward and backward pass. This is used for regularization and saves your model from overfitting. No learning happens in this layer.
Line 7- The layer c1 after dropout is convolved again with 16 filters of each size 3x3. The activation and weight initializer remain the same.
I just love how these baby filters have grown up from image processing to deep learning. Yes, I do. I remember using one, two, three and many filters which were designed after years and years of analysis on huge datasets, and now things have grown up. The filters are designing themselves. Fills me with happiness always.
Line 8- The output of the convolution layer c1 now goes into the max-pooling layer. The window size of the max-pooling layer m1 is 2x2.
I would like to share one more experience of mine. Recently I was asked a question “ When we convolve an image with filters the dimensions of the image get reduced and you must be aware that max-pooling does the same, it reduces the dimension. Then why do we use convolution or max-pooling separately? we can just either use convolution or max-pooling”. This is a good question and this made me reflect back and my reply was “ Convolution layers are responsible for extracting image features, building the filters, and in this process, the dimension of the image gets reduced, lots of parameters are learned in this layer. But in the max-pooling layer, no parameters are learned. Max-pooling layers help us handle the data in the most efficient way by considering only the best possible representation of available data/features. That is why we use convolution layers and the max-pooling layers separately”
Line 10 to 13- In this block of code you can find a similar structure to the code block as is present in line 5 to 8. The convolution layer followed a dropout and then a convolution again and max-pooling. I have doubled the number of filters from 16 to 32 in this block. The dropout is still 0.1. You are free to play with these hyperparameters. I do not want to drop a huge amount of nodes as I will be using these layers information to preserve the contextual information in coming layers. I would also recommend you keep the dropout percentage small.
Line 20 to 27- You can see that there are two blocks of code similar to above it. You should notice the change in the number of filters used. The number of filters just got doubled.
Line 29 to 51- I want to bring your attention to these significant lines.
u6 = Conv2DTranspose(128, (2, 2),strides=(2, 2),padding='same') (c5)
u6 = concatenate([u6, c4])Here, you can see two new layers called Conv2DTranspose and concatenate. First, let us understand the functions of Conv2DTranspose. The need for transposed convolutions generally arises from the desire to use a transformation going in the opposite direction of a normal convolution, i.e., from something that has the shape of the output of some convolution to something that has the shape of its input while maintaining a connectivity pattern that is compatible with said convolution. As our aim is also to reproduce a mask similar to the input mask dimensions, we use Transpose convolution.
In the above block of code, you can see that we use 128 filters each of size 2x2 and strides 2 on the output from later c5. Once we have upsampled it the output is u6. The best and most important part about this model is the concatenate layer which concatenates outputs from two layers, one from the left part of its U shaped network and another from the right part of its U shaped network.
In the above code block, you can see that output from convolution layer 4 before max-pooling is concatenated with the output from layer U6. This is done to preserve the contextual information of one pixel to its neighbor pixel (left pixel, right pixel, diagonal pixel, etc,.). We all know that the earlier layers of the convents learn minor features and they have more information about edges, curves, etc. Using them or concatenating them with later layers will be an advantage to yield more accurate segmentation as they carry contextual information.
Similarly, there are four blocks in the right part of U-Net architecture. Every block has one Transpose convolution layer, one concatenate layer, two convolution layer, one dropout layer.
Line 53- This is a fully convolutional deep learning model so there are no dense layers. The last layer is a convolution layer. The activation function used is sigmoid as I have only 2 classes. A building and background on the 2D satellite map image. You must use softmax if you wish to train the model for more than 2 classes.
Line 55 to 57- The loss function which I have used here is binary cross-entropy because I am working with binary classes. You must replace it with the categorical-cross entropy if you are working with more than two classes. I am using Adam as an optimizer. In Adam, a learning rate is maintained for each network weight (parameter) and separately adapted as learning unfolds. The metric used here is mean IOU. Metric does not play any role in the learning, it is just there so that you can visually compare the training with something other than the loss function. You can print the summary of the model on your console using Keras summary() command.
Line 2- Early stopping helps you to stop and save the model if the validation loss does not decrease for some consecutive epochs. In the code, you can see I have mentioned patience =5 which means during training if the validation loss does not increase for 5 consecutive epochs the training should stop and save the model. The model would contain the network and its learned weight, which you can use to predict results on new images.
Test U-Net model
The above code is used for testing where we are loading our trained model (u can find the trained model in the test folder) and testing the results on a test image (size of the test image must be 128x128x3, you can find a few sample test image in the test_128 folder inside the test folder). Since we get a binarized output so if the output pixel is a 0 we assign it an intensity 0 and if the output pixel intensity is a 1 we assign it an intensity 255. The prediction accuracy is threshold is 0.5. Also, the data which I had used to train the model has privacy concerns. Respecting that, I have shared similar test images. Also inside the data folder, I have put a different dataset so that it can help you to understand how you have to structure your custom dataset.
Analysis of results

I used 720 images to train and 180 images to test the U-Net model. I have achieved a validation loss of 0.31558 and IOU accuracy 0.6293 when trained on 720 images for 30 epochs. The validation loss was 0.8973 when I had trained the model on 128 images. There are multiple factors in the increase and decrease in the loss and IOU values, it's not just the number of images.
I am suggesting a few improvements in the data and model base on my observation in the next section.
Improvement suggestion
- Using the residual network in the encoder part. If using large skip connections can help enhance the results, one can try using the residual network in the encoder part.
- If your hardware allows you to train on big images. If you have good memory bandwidth, I would always recommend you to use images with dimension 512X512X3, 572x572x3.
- My data also lacked in quality. The images had very low contrast. But that is how the natural scene would be. I did not do any pre-processing on the images but it would be really interesting to see improving or decreasing results after pre-processing the images.
- I would recommend using batch normalization after activation function which will help your model to regularize and learn faster.
- I would also want to see how using relu helps the model and what effects can we see in the convergence rate.
- Padding is important as we are missing lots of information from the border area. I have not padded my images. So if your aim is also to predict accurate information from the image border, you must consider padding the images while training.
Conclusion:
Writing this article had a motive.
The motive is to document my learning at the same time sharing it with people who might need this. I would request you to feel free to ask me any question related to the model and how you can implement the suggestion. I would also recommend you to read the part-1 of this blog series as I have explained the complete model in detail step-by-step.
Thank you for your time. Please give your kind feedback in the comment section, that would help me to improve my work.

References:
